Harness Engineering:为什么 2026 年决定 Agent 上限的,不再是 Prompt,而是运行环境
当大家还在讨论 prompt 和 context 时,真正把 Agent 推向生产的关键已经转向另一层:状态、工具、护栏、评估、可观测性与长期运行机制。Harness Engineering 正在成为 2026 年最重要的 AI 工程主题之一。
如果你最近还在刷 AI Agent 相关内容,应该已经明显感觉到一个变化:讨论的重点,正在从“怎么把 prompt 写得更好”,慢慢转向“怎么让 Agent 在真实世界里连续工作,并且不失控”。
这不是一个小变化,而是一个范式切换。
过去两年,大家已经把 Prompt Engineering 说得足够多了。后来,随着 RAG、长期记忆、工具描述、工作流编排的兴起,更多人开始用一个新的词来描述进阶阶段:Context Engineering。它强调的不是单次提问的文案技巧,而是如何把对模型真正有用的信息,在每一步推理前准确地喂进去。
但到了 2026 年,这两层都开始显得不够了。
原因很简单:当模型从一次性回答问题,升级为要在几分钟、几小时、甚至跨多天去完成复杂任务时,真正决定成败的,已经不再只是 prompt 本身,也不再只是上下文组织,而是整个运行系统。
一个今天被频繁提起的新词,正好用来描述这件事:Harness Engineering。
这个词可以翻译成“驾驭工程”“缰绳工程”或者“Agent 运行环境工程”。不管怎么翻,它指向的都是同一件事:为了让一个 LLM 真正成为可控、可测、可恢复、可长期运行的 Agent,我们必须围绕模型构建一整套约束、状态、工具、验证和反馈系统。模型只是引擎,Harness 才是整辆车。
我觉得这是今年最值得认真理解的一个概念。因为它不是某家公司的新 marketing 口号,而是 OpenAI、Anthropic、LangChain、Firecrawl、Terminal-Bench 这些不同阵营,几乎同时在强调的一层现实:Agent 的瓶颈越来越不在“会不会回答”,而在“能不能可靠地干活”。
这篇文章我想做三件事。
第一,把 Harness Engineering 这个词讲清楚,避免它变成又一个模糊流行词。
第二,把 OpenAI、Anthropic、LangChain、Terminal-Bench 和 Firecrawl 的一手材料串起来,解释为什么这个概念会在 2026 年突然变得重要。
第三,尝试回答一个更现实的问题:对于开发者和团队来说,Harness Engineering 到底意味着什么,它会不会成为下一阶段 AI 工程的核心能力。
为了更直观地理解它到底在管什么,可以先看一张架构图。你会发现,Prompt 和 Context 只是其中两块,真正把 Agent 变成可运营系统的,是外层那套 runtime、状态、工具、护栏、评估和反馈闭环。
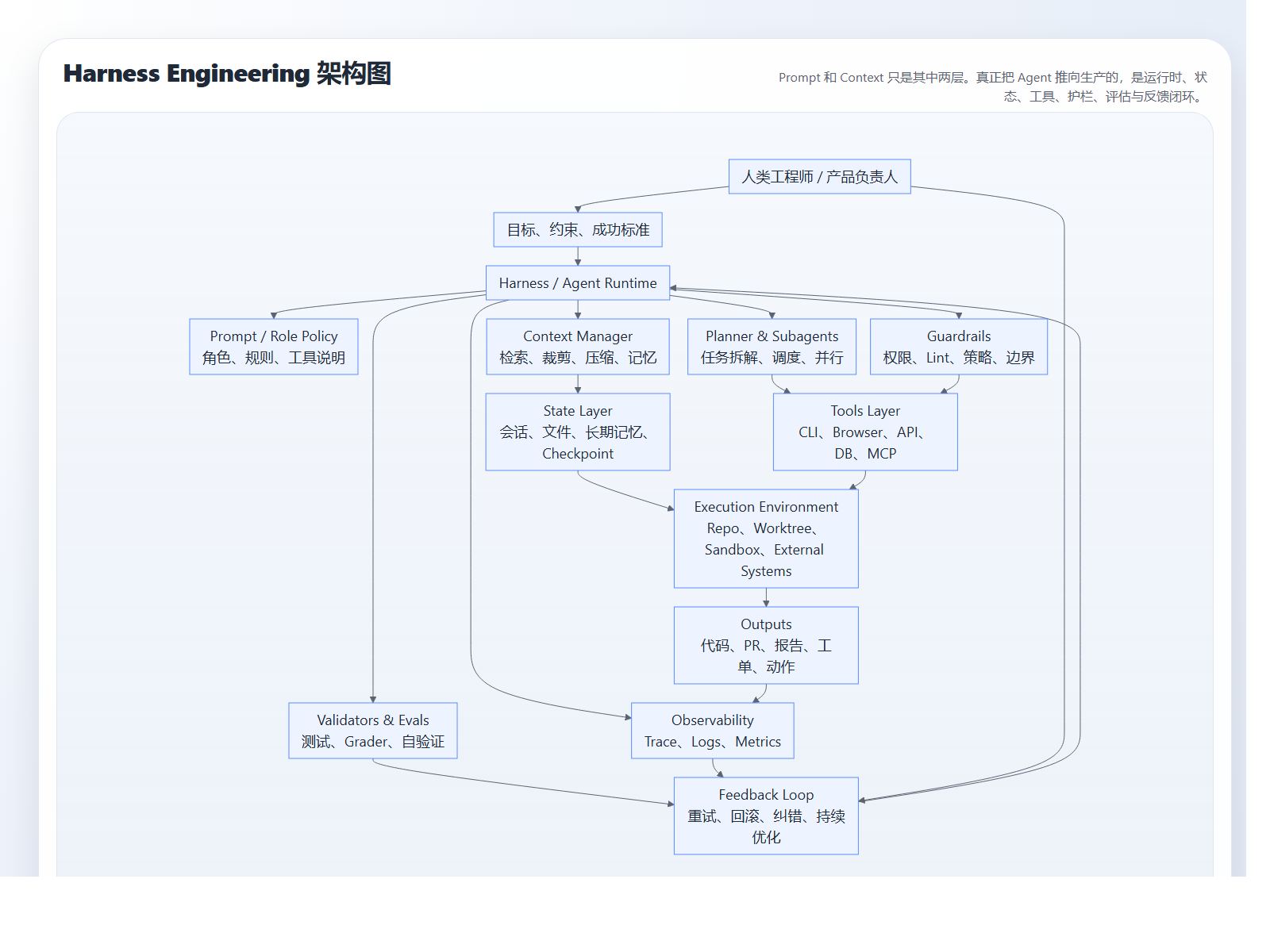
一、从 Prompt 到 Context,再到 Harness:这条演化链为什么是必然的
如果把过去两三年的 AI 工程演进抽成一条主线,大致可以这样看:
- Prompt Engineering 解决的是“单次调用,怎么说模型才更容易听懂”
- Context Engineering 解决的是“多轮调用里,到底哪些信息应该进入上下文”
- Harness Engineering 解决的是“在模型之外,整个 Agent 系统如何被约束、编排、验证和维护”
这里有一个非常关键的判断:Harness Engineering 不是 Prompt Engineering 的替代品,也不是对 Context Engineering 的否定,而是把前两者都纳入一个更大的系统视角。
Prompt 仍然重要。系统提示、工具说明、few-shot 示例、角色边界,这些东西今天依旧是有效的。Anthropic 在关于 Context Engineering 的文章里明确说过,Prompt Engineering 仍然是构建 Agent 的重要组成部分,只是它不再是全部。Anthropic《Effective context engineering for AI agents》
Context 也依然重要。尤其当 Agent 进入循环执行、长期运行和多工具协作阶段时,上下文管理几乎决定了模型每一步会不会“走神”。Anthropic 也特别强调,LLM 的上下文不是越多越好,而是一种有限的注意力预算;当上下文不断膨胀时,模型会出现明显的“context rot”。Anthropic《Effective context engineering for AI agents》
但问题在于,即便你 prompt 写得很好、context 管得很精致,Agent 依然会在真实环境里翻车。
它可能:
- 在一个错误分支里反复重试,形成死循环
- 误用工具,甚至调用根本不该调用的命令
- 生成看起来正确、实际未经验证的结果
- 在跨会话任务中丢失关键状态
- 在上下文变长后忘掉核心约束
- 通过“合理但错误”的方式完成任务,最后结果完全不可用
这就是为什么 Harness Engineering 会出现。因为一旦任务从“回答一个问题”变成“连续工作并交付结果”,工程师就不得不面对一个很现实的事实:
LLM 并不是完整系统,它只是一段高维推理能力。真正把它变成产品的,是包裹在外面的那层运行机制。
Firecrawl 在解释 Agent Harness 时说得很直白:Prompt Engineering 只是在优化一次模型调用;Context Engineering 设计的是每一步应该进入上下文的信息;而 Harness 则进一步负责工具执行、状态存储、会话管理和错误恢复,也就是那些“发生在上下文窗口之外,但却决定系统能否工作”的部分。Firecrawl《What Is an Agent Harness?》
我觉得这是理解整个概念最好的切口。
如果 Prompt 是你对驾驶员说的话,Context 是地图和沿途信息,那么 Harness 就是整条高速公路本身:车道线、护栏、收费站、应急车道、监控、限速标志、导航联动、故障救援。没有这套基础设施,再好的司机也很难稳定跑长途。
二、Harness Engineering 到底在说什么:它不是某个框架,而是一层系统职责
到这里,一个常见误解需要先拆掉:Harness Engineering 不是某个具体开源框架的名字。
它不是 LangGraph,不是 Deep Agents,不是 Claude Agent SDK,也不是 Harbor。它更像是一层工程职责,一组设计目标,一类系统方法。
Anthropic 在讨论 Agent evals 时给了一个非常清晰的区分:
agent harness(或 scaffold) 是让模型“能作为 agent 行动起来”的系统;
evaluation harness 则是让你“能够评估这个 agent 到底行不行”的系统。
这两个概念相关,但并不相同。Anthropic《Demystifying evals for AI agents》
这个区分非常重要,因为很多团队现在做 Agent 时,把“能跑起来”和“能被验证”混成了一件事。其实它们至少是两层:
1. Agent Harness:让模型有能力长期行动
这一层包括但不限于:
- 工具注册与执行
- 状态持久化
- 会话恢复
- 子代理编排
- 权限控制
- 上下文压缩与裁剪
- 失败重试与回滚
- 任务拆解与调度
Claude Agent SDK 的文档里就很典型。它强调 SDK 不只是发请求,而是直接给你提供文件读取、命令执行、Web 搜索、MCP、权限、会话、Subagents、Hooks 等一整套能力,等于把“Claude Code 那层实际让模型干活的东西”程序化暴露出来。Claude Agent SDK 文档
2. Evaluation Harness:让你知道它到底是不是可靠
Anthropic 在 evals 文章里给出的定义很值得抄下来反复看:evaluation harness 负责运行任务、并发执行、记录 transcript、调用 grader、汇总结果。换句话说,你不是凭感觉觉得 agent 变好了,而是通过任务、试次、结果状态、评分器和轨迹记录,系统地知道它哪里变好了、哪里还不行。
这一层常常包括:
- 基准测试集
- 任务环境
- 评分器/验证器
- 结果聚合
- 失败轨迹记录
- 对照实验
也正因如此,我更倾向于把 Harness Engineering 理解为一个总括性词:它涵盖了让 agent 运行起来的系统设计,也涵盖了让它能被评估和迭代的反馈回路。
如果说 Prompt Engineering 的焦点是“写一句好指令”,Harness Engineering 的焦点就是:
如何把模型包进一个可运营、可调试、可验证、可长期维护的系统里。
三、为什么 2026 年大家突然都在谈 Harness:因为真实世界已经逼到这一步了
很多概念的流行,往往不是因为定义得更漂亮,而是因为老办法已经不够用了。
Harness Engineering 在 2026 年突然升温,我觉得至少有四个现实原因。
1. Agent 的任务时长变了
以前我们默认一次交互十几秒结束。现在不一样了。
OpenAI 在讲自己内部用 Codex 构建产品的文章里提到,他们有单次运行持续六小时以上的 agent;并且他们刻意采用“0 行人手代码”的约束,逼着团队去建设能让 agent 真正持续工作的环境。OpenAI《Harness engineering: leveraging Codex in an agent-first world》
当运行时间从秒级变成小时级时,很多以前不存在的问题都会出现:
- 上下文如何压缩
- 日志和观测数据怎么暴露给 agent
- 如何在 worktree 里起多个隔离实例
- PR 如何被 agent 自审、自修、自迭代
- 技术债怎么被持续清理而不是每周人工“扫屎”
这已经远远超出 prompt 的范畴了。
2. Agent 的失败方式越来越“工程化”
传统聊天模型的失败,通常表现为答错、答偏、答得空泛。但 Agent 的失败要复杂得多。
它可能不会直接说错话,而是:
- 在错误路径上走得很认真
- 用了看似合理、实际上不允许的工具
- 在未验证的假设上构建后续步骤
- 因为一个局部误判导致整个长链条任务崩盘
这也是为什么 Andrej Karpathy 对当前 Agent 的评价会那么尖锐。围绕他那句 “They just don’t work” 的传播很多,但真正值得记住的不是情绪,而是背后的数学直觉:多步系统会让单步错误率被指数放大。即使每一步看起来都还行,只要链条足够长,最终任务成功率就会快速塌缩。
这类问题,本质上不是“模型更聪明一点”就能自然解决的,它们需要护栏、验证、状态管理、轨迹分析这些工程层能力。
3. 大家终于开始有比较统一的测量方式
一个概念能真正落地,往往要等到它能被测量。
Terminal-Bench 2.0 的重要性就在这里。它不是在做“聊天质量测评”,而是在测 agent 在真实终端环境里完成长任务的能力。论文里明确写到:Terminal-Bench 2.0 包含 89 个来自真实工作流启发的困难任务,每个任务都带有独立环境、人工编写解法和完整验证测试;而前沿模型与 agent 在这个 benchmark 上的得分依然低于 65%。Terminal-Bench 论文
这组数据之所以重要,是因为它直接戳破了很多表面上的“Agent 很强”。如果一个系统在公开视频里很会 demo,但在一套高质量、可验证、长链条的真实任务集合上仍然经常失败,那你就必须正视:问题可能不在“文案怎么写”,而在 harness 设计。
4. 框架和产品开始把“运行时”显式暴露出来
以前很多团队自己偷偷写一套 agent runtime,但不太会把它当成独立概念来讲。到了 2026 年,这层东西开始被公开命名、公开文档化。
Anthropic 直接把 Claude Code 背后的 agent harness 能力抽出来做成 SDK。
LangChain 不再只讲 agent abstraction,而开始明确讲 “Deep Agents” 和 harness capabilities。
OpenAI 公开讲自己的内部 harness 是怎么把一个 product 运行起来的。
Firecrawl 也在解释:所谓 agent harness,解决的是 stateless LLM、finite context、tool hallucination 和 multi-session continuity 这些具体问题。Anthropic SDK 文档 LangChain Deep Agents Firecrawl《What Is an Agent Harness?》
也就是说,这不再只是“社区自嗨的新词”,而是主流玩家在同一时间都开始显式描述的一层共同结构。
四、Harness 的核心组件到底有哪些:如果拆开看,它其实非常工程化
如果把各家的实践放在一起看,我觉得一个比较稳妥的拆法,大概是下面六层。
1. 状态与持久化
Agent 一旦要跨多轮、跨工具、跨会话工作,状态就必须从“模型记忆”变成“系统资产”。
这包括:
- 当前任务状态
- 已完成和未完成子任务
- 关键中间产物
- 会话摘要
- 可恢复的 checkpoint
- 长期偏好和项目记忆
Anthropic 在 Agent SDK 相关文章里提到,长时间运行的 agent 需要 compaction 来维护上下文;文件系统结构本身也会变成一种 context engineering;而 subagents 则能通过上下文隔离减轻主线程负担。Anthropic《Building agents with the Claude Agent SDK》
这意味着:状态并不是“多存点历史消息”那么简单,而是要能被精简、恢复、选择性读取和跨线程管理。
2. 工具层与权限边界
很多 agent 之所以危险,不是因为它会说错,而是因为它会“做错”。
一旦模型获得 bash、文件编辑、浏览器、数据库、API、邮件、支付等工具,系统就必须回答几个问题:
- 它可以用哪些工具
- 在什么上下文下允许调用
- 工具参数如何校验
- 工具返回结果是否可信
- 调用失败后怎么处理
Anthropic SDK 把允许工具、权限边界、MCP、Hooks 都显式做成一等能力,这本身就是一种信号:Agent 的可用性不再只是看模型是否会调用工具,而是看整个工具权限体系是否被工程化。Claude Agent SDK 文档
3. 约束与护栏
OpenAI 那篇关于 Codex harness 的文章里有一句我觉得非常关键的话:他们不是去微观规定 agent 每一步要怎么做,而是强制边界、允许边界内自治。OpenAI《Harness engineering》
这听起来像平台工程,但恰恰是 agent 时代最重要的组织思想之一。
护栏可以是:
- 自定义 lint
- 架构依赖方向检查
- schema 验证
- 权限白名单
- 结构测试
- 运行时策略引擎
有些团队会把这类东西误以为是“限制模型创造力”,但从 agent 系统角度看,它们恰恰是在放大创造力。因为约束一旦写进系统,就不需要人再重复盯同样的问题。
4. 验证与评估
Harness 不是把模型包起来就结束了,它还必须能被持续度量。
Anthropic 对 eval 的定义非常值得抄作业:任务、试次、grader、transcript、outcome、evaluation harness。这套定义的价值不在名词,而在它逼着工程团队把“AI 系统的变化”从主观印象转成可重复实验。Anthropic《Demystifying evals for AI agents》
没有这一层,你很容易陷入一种幻觉:这周好像变聪明了,下周又好像变笨了,但没人说得清到底发生了什么。
5. 可观测性与轨迹分析
LangChain 在提升 Deep Agents 的案例里强调,他们是通过 traces 去理解 agent 在文本空间里的失败模式,再把这些失败转成 harness 优化的输入。LangChain《Improving Deep Agents with harness engineering》
这一点特别重要。因为模型内部权重基本黑箱,但 agent 外部行为不是。我们至少可以看到:
- 输入了什么上下文
- 做了哪些工具调用
- 每一步为什么偏航
- 在哪个阶段损失了关键信息
- 是模型能力不够,还是 harness 提供了错误诱导
如果没有 trace,团队只能靠猜。如果有轨迹,很多“模型不行”的锅其实会被重新分配到系统设计上。
6. 熵控制与持续清理
这是我觉得最容易被忽略、但又最能体现 2026 年 agent 工程新现实的一层。
OpenAI 在内部 Codex 实验里提到,他们最早每周都要花一天时间清理 “AI slop”,后来把“黄金原则”和后台清理任务编码进仓库,让 agent 自己持续扫描偏差并发起小 PR,像垃圾回收一样控制熵。OpenAI《Harness engineering》
这个细节太重要了。
因为一旦 codebase 大量由 agent 生成,问题不再只是“能不能生成”,而是“如何不让它越来越乱”。Harness 的一部分职责,正是让系统有能力持续对抗自身产生的熵。
五、最有说服力的案例:同一模型,只改 harness,成绩就能明显提升
如果说前面还只是概念阐释,那 LangChain 的例子就是最直接的证据。
在 2026 年 2 月的文章里,LangChain 公开写到,他们把自家的 coding agent deepagents-cli 在 Terminal-Bench 2.0 上从 52.8% 提升到 66.5%,提升了 13.7 个百分点,而他们强调的一点是:模型没有换,改的是 harness。LangChain《Improving Deep Agents with harness engineering》
这意味着什么?
意味着在当前阶段,很多 agent 的上限并不完全受制于基础模型,而是深受外部系统设计影响。
LangChain 总结的做法里,我觉得最值得记住的几条是:
- 用 traces 理解失败模式,而不是靠感觉猜
- 为模型加入自验证流程
- 通过工具与约束减少模型常见失误
- 根据具体模型去定制 harness,而不是假设所有模型在同一 harness 下表现相同
这最后一点尤其重要。
LangChain 在文中明确提到,不同模型需要不同 prompting 和 harness 设计。Claude 和 Codex 在同一个 agent 任务上未必吃的是同一套最优 scaffold。换句话说,未来模型竞争和 harness 竞争会越来越耦合。
这也解释了为什么 LangChain 在另一篇《The Anatomy of an Agent Harness》里强调,模型训练和 harness 设计正在形成反馈回路:有用的 harness 原语被发现、被系统化,然后又被下一代模型在训练中“习惯化”。LangChain《The Anatomy of an Agent Harness》
所以我们今天看到的,不只是“框架层技巧”,而是在看一个新的 co-evolution 周期:模型和 harness 正在共同进化。
六、OpenAI 和 Anthropic 的共同信号:人类工程师的工作,正在从写代码转向设计环境
如果只看 LangChain,你还可以说这是框架公司的叙事;但当 OpenAI 和 Anthropic 也在不同角度给出类似信号时,事情就很值得认真对待了。
OpenAI 的信号:人类“设计环境”,agent“执行工作”
OpenAI 那篇文章里有一条我觉得最值得记住的句子:Humans steer. Agents execute.
他们不是把 agent 当成“更快的 autocomplete”,而是在内部真实产品环境里,把人类工程师的主要工作重心,转向设计环境、提供能力、编码反馈回路、提升系统可读性和可验证性。文章里提到的实践包括:
- 让应用可以按 git worktree 启动,方便并行 agent 工作
- 把 UI、日志、指标、trace 变成 agent 可读上下文
- 用 custom lints 把架构边界变成硬约束
- 通过后台 agent 做“垃圾回收”,持续纠正模式漂移
这套做法本质上是在说:当主要执行者不再是人,而是 agent 时,工程师的价值越来越体现为“搭平台”和“设规则”。
Anthropic 的信号:真正可用的 agent 必须围绕长期运行来设计
Anthropic 这边的信号略有不同。他们没有那么强调“零手写代码”的实验性,而是更聚焦长期运行 agent 的真实工程问题:
- context 会膨胀,必须 compaction
- subagents 的价值不仅是并行化,更是上下文隔离
- 文件系统结构本身会变成 context engineering 的一部分
- eval 不能只看最终一句回答,而要看完整 transcript、outcome 和 grader 结果
这些细节都在告诉我们:一旦 agent 真正进入复杂任务场景,系统工程会迅速压过 prompt 技巧,成为决定可用性的主战场。
我觉得 OpenAI 和 Anthropic 在这里给出的其实是同一个信号,只是切入点不同:
- OpenAI 更像在展示“如何把 agent 纳入真实工程生产线”
- Anthropic 更像在拆解“长期运行 agent 为什么会失控,以及要怎样才能控制”
两者拼起来,就是我们今天理解 Harness Engineering 最完整的一张地图。
七、Harness Engineering 不是万能药:它解决的是系统问题,不是魔法问题
说到这里,也必须泼一点冷水。
我并不认为 Harness Engineering 代表一个“只要搭好架子,任何模型都能变强很多”的神奇时代。它解决的是一类很具体、很现实的问题,但它并不自动解决另外一些更本质的限制。
它不能凭空创造模型没有的推理能力。
它不能让弱模型突然学会复杂领域知识。
它也不能完全避免长链路任务里的非确定性。
更准确地说,Harness Engineering 做的是三件事:
- 减少本不应该发生的低级失误
- 提高系统在长任务中的稳定性与恢复能力
- 让团队可以更快发现和纠正 agent 的失败模式
这已经非常重要,但这不是魔法。
如果一个团队把 Harness 当成“万能补锅器”,那很容易走进另一个坑:系统越来越复杂,Agent 反而越来越难调。
所以我觉得最成熟的态度应该是:Harness 不是用来掩盖模型能力不足,而是用来把已有模型能力可靠地释放出来。
这也是为什么 Anthropic 和 LangChain 都反复强调 eval、trace、tool design 和 just-enough constraints。不是堆更多复杂度,而是把必要复杂度放在最值钱的地方。
八、对开发者和团队来说,真正的变化是什么
如果 Harness Engineering 真的会成为接下来几年 AI 工程的核心主题,那它带来的变化,远不只是“多学一个新术语”。
我觉得至少有三层变化。
1. 开发者的核心能力会重新排序
未来高价值开发者,未必是写业务代码最快的人,而更可能是最会做下面这些事的人:
- 设计 agent 的工作边界
- 把任务切成适合 agent 处理的单元
- 把团队经验编码成规则、工具和验证器
- 建立上下文系统,而不是手工补上下文
- 从 trace 里定位系统性失败,而不是只怪模型“又抽风了”
这其实是一种很明显的角色升级:从“执行器”转向“环境设计师”。
2. 团队会越来越像在建设 AI 平台,而不是 AI 功能
很多公司今天做 AI,还停留在功能层:搞一个聊天入口、接一个模型、封一层接口。
但 Harness Engineering 的视角会逼着团队往更底层看:
- 任务怎么定义
- 状态怎么保存
- 工具怎么授权
- 结果怎么验证
- 失败怎么恢复
- 成本怎么监控
- 行为怎么追踪
- 漂移怎么治理
一旦你开始认真回答这些问题,你做的就已经不只是某个 AI feature,而是一套 AI 运行平台。
3. Agent 产品的护城河会逐渐转向系统设计
接下来模型仍然会进步,这点几乎不用怀疑。但随着更多团队都能接到足够强的基础模型,差异化竞争会越来越发生在 harness 层。
谁能让 agent:
- 更稳地跨多轮完成任务
- 更便宜地运行长任务
- 更清楚地暴露错误原因
- 更快地迭代失败样本
- 更安全地调用高风险工具
- 更自然地融入团队已有工作流
谁就更有机会在产品层形成优势。
这也是为什么我觉得 Harness Engineering 很可能不是一阵风,而会成为未来两三年里最实打实的 AI 工程能力之一。
结语:2026 年最值得警惕的误解,是把 Agent 问题继续当成 Prompt 问题
如果非要用一句话总结我对 Harness Engineering 的理解,那大概是:
当 Agent 开始真正工作时,决定上限的已经不是你对模型说了什么,而是你给模型安排了怎样的世界。
这句话里,“世界”包括:
- 它能看到什么
- 它能记住什么
- 它能做什么
- 它做错了以后谁来拦
- 它完成之后谁来验
- 它失败之后如何恢复
- 它长期运行后如何对抗熵增
Prompt 当然还重要,Context 当然也仍然关键。但把 Agent 做进生产,真正要解决的问题,已经越来越像传统软件工程里的那些硬问题:状态、接口、权限、验证、监控、维护、架构边界、技术债治理。
这也是 Harness Engineering 最有意思的地方。它表面上看像一个新词,实际上却把我们重新带回一个非常古老、也非常严肃的工程问题:
能力从来不是凭空可用的。任何强大的智能,最终都需要一个能把它约束成生产力的系统。
我觉得 2026 年最值得重视的,不是“又出现了一个什么新 agent 框架”,而是越来越多团队终于开始承认这件事:AI Agent 的竞争,正在从模型调用技巧,转向运行环境设计。
如果这个判断成立,那么未来真正优秀的 AI 工程师,可能不再是“最会写 prompt 的人”,而会越来越像“最会设计 agent 基础设施的人”。
而这,才是 Harness Engineering 这个词真正值得被认真对待的原因。
参考资料
- OpenAI《Harness engineering: leveraging Codex in an agent-first world》
- Martin Fowler《Harness Engineering》
- LangChain《Improving Deep Agents with harness engineering》
- LangChain《The Anatomy of an Agent Harness》
- Anthropic《Demystifying evals for AI agents》
- Anthropic《Building agents with the Claude Agent SDK》
- Anthropic《Effective context engineering for AI agents》
- Claude Agent SDK 文档
- Firecrawl《What Is an Agent Harness?》
- Terminal-Bench 2.0 论文
- Terminal-Bench《Introducing Terminal-Bench 2.0 and Harbor》
Published on 2026-03-31